
python爬虫不可不知的10个高效数据清洗方法 (四 ) 布隆过滤器
8. 布隆过滤器 去重+节约空间的好帮手
布隆过滤器(Bloom Filter)为了解决海量数据的存在性问题。
对于海量数据中判定某个数据是否存在且容忍轻微误差这一场景(比如缓存穿透、海量数据去重)来说,非常合适。
如果不了解也没关系,下面看一个例子:
有100瓶药水,其中一瓶是毒药,只要一小滴,就足以让小白鼠24小时内死亡。请问怎么在1天内用最少的老鼠找出这瓶毒药?
可能有人会说,我用100只小白鼠就可以知道毒药是哪瓶了,所以小白鼠是招你还是惹你了,非要搭上一整个家族来给你找毒药?其实这个问题答案很简单,我们只需要7只小白鼠就够了,而这个问题的解题关键就是数学编码中的二进制。
一、如何用7只小白鼠找毒药 二进制编码
第1布:我们对100个瓶子进行1~100号的编码,再转化为7位的二进制码(至于为什么是7位,看到后面你就懂了)**。比如1号瓶子就转化为了“0000001”,10号瓶子就转化为了“0001010”:

第2步:找来7只小白鼠,分别对他们进行1~7的编号。对于编号是1的小白鼠,喂它所有二进制编码第1位(从左到右数)为1的瓶子;对于编号2的小白鼠,喂它所有二进制编码第2位(从左到右数)为1的瓶子;以此类推…
第3步:接下来就是看一天后哪几只老鼠挂了:如果某个编号的老鼠死了,那说明毒药瓶子的二进制编码在对应编号位置上的二进制值是1;反之如果某个编码的老鼠没有死,那说明毒药瓶子的二进制编码在对应编号位置上的二进制值是0。
假如最后是2,4,5,7号老鼠挂了,那说明对应的毒药瓶子二进制编码是“0101101”,转化成十进制,即第45号瓶子是毒药。
这个例子用来说明,如果要定位某个元素在100个元素的位于哪个位置,只需要7 >= lg(100)/lg(2) 就可以了。
这个就是布隆去重过滤器的基本原理。
编程实现
布隆去重过滤器 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 布隆去重过滤器 节省内存的核心所在。
这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。

这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
核心操作逻辑:
添加元素时:
- 用多个哈希函数计算元素的哈希值;
- 根据哈希值,将位数组对应下标的值置为 1。
判断元素是否存在时:
- 对元素进行相同的哈希计算;
- 若位数组中所有对应位置均为 1,则认为元素存在;若有一个位置为 0,则元素不存在。
布隆过滤器的原理图如下:
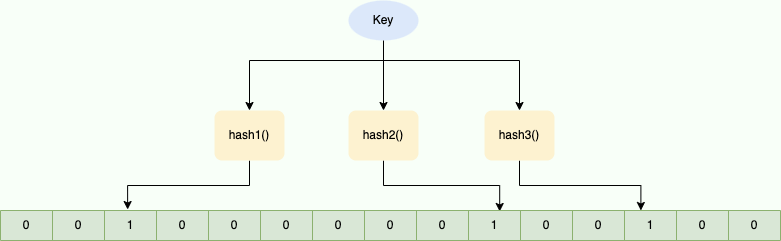
当字符串加入布隆过滤器时,会通过多个哈希函数生成不同的哈希值,然后将位数组对应下标置为 1(初始化时所有位置为 0)。再次添加相同字符串时,对应位置已为 1,即可判断已存在(去重方便)。
注意: 不同字符串可能哈希到相同位置,可通过增加位数组大小或调整哈希函数减少冲突。
综上:布隆过滤器说元素存在,可能误判;说元素不存在,则一定不存在。
接着我们使用python实现一个布隆过滤器。
# -*- coding: utf-8 -*-#
# 提供二进制向量
from bitarray import bitarray
# 提供hash函数mmh3.hash()
import mmh3
class BloomFilter(set):
"""
size: 二进制向量长度
hash_count: hash函数个数
一般来说,hash函数的个数要满足(hash函数个数=二进制长度*ln2/插入的元素个数)
"""
def __init__(self, size, hash_count):
super(BloomFilter, self).__init__()
self.bit_array = bitarray(size)
self.bit_array.setall(0)
self.size = size
self.hash_count = hash_count
def __len__(self):
return self.size
# 使得BloomFilter可迭代
def __iter__(self):
return iter(self.bit_array)
def add(self, item):
for ii in range(self.hash_count):
# 假设hash完的值是22,size为20,那么取模结果为2,将二进制向量第2位置为1
index = mmh3.hash(item, ii) % self.size
self.bit_array[index] = 1
return self
# 可以使用 xx in BloomFilter方式来判断元素是否在过滤器内(有小概率会误判不存在的元素也存在, 但是已存在的元素绝对不会误判为不存在)
def __contains__(self, item):
out = True
for ii in range(self.hash_count):
index = mmh3.hash(item, ii) % self.size
if self.bit_array[index] == 0:
out = False
return out
def main():
bloom = BloomFilter(100, 10)
urls = ['www.baidu.com','www.qq.com','www.jd.com','www.xiaomi','www.mi.com']
# 新增过滤规则
for url in urls:
bloom.add(url)
# 已经插入的url应该绝对满足存在
for url in urls:
if url in bloom:
print('{}在布隆过滤器中......'.format(url))
else:
print('{}不在布隆过滤器中......'.format(url))
print('\n')
print('这是分割线', '-'*100)
print('\n')
other_animals = ['www.baidu.com','www.bai.com','www.tencent.com','www.360.com']
for other_url in other_urls:
if other_url in bloom:
print('{}在布隆过滤器中......'.format(other_url))
else:
print('{}不在布隆过滤器中......'.format(other_url))
if __name__ == '__main__':
main()上述代码,二进制数组是保存在内存里,断电,或者分布式爬虫就会不适用。
此时,就需要用到redis,多个爬虫共同访问同一个redis数据库,如果主机A已经爬过A网站,把A的哈希转换成位数,保存到redis。那么主机B把A网站网址哈希位到redis查询,查到有,就证明A网站已经爬取过了,就没必要再重复爬取了。
使用redis作为布隆过滤器:
安装redis库:
pip install redis同时需要有一台redis服务器,可以在本地安装,安装过程很简单,体积也很小。
import redis
def main():
# 连接到Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 创建布隆过滤器
r.execute_command('BF.RESERVE', 'myBloomFilter', 0.01, 100000)
# 添加元素
items = ['url1', 'url2', 'url3', 'url4']
for item in items:
r.execute_command('BF.ADD', 'myBloomFilter', item)
# 查询元素
test_items = ['url5', 'url6', 'url7','url8']
for item in test_items:
exists = r.execute_command('BF.EXISTS', 'myBloomFilter', item)
print(f"Item '{item}' exists: {'Yes' if exists else 'No'}")
if __name__ == "__main__":
main()Code language: PHP (php)分布式爬虫场景中,只需将 Redis 连接地址改为公共服务器地址,即可实现多节点共享去重逻辑。