
Scrapy Redis:概述
数据挖掘、信息处理和历史保存只是 Web 爬行和结构化数据提取应用程序框架(称为 Scrapy Redis或Redis Scrapy)的一小部分用途。它是一种内存数据结构,用作数据库、缓存或消息代理。它是开源的,并支持使用超日志和空间索引进行scrapy ip 代理搜索。因此,它对于网络抓取至关重要。
什么是 Scrapy Redis?
一个名为 scrapy Redis 的键值对数据存储是一个 NoSQL 系统。准确地说,它是数据结构的服务器。 Redis 可以用作适当的数据库,不仅是临时缓存,因为它可以持久保存到磁盘。
当我们恢复时,数据不会像 Memcached 那样丢失。它速度极快,通常甚至比 Memcached 还要快,因为它与 Memcached 一样,将整个数据集保存在内存中。 Redis 使用虚拟内存,将很少使用的值交换到磁盘,只将键留在内存中,但这种做法后来被放弃了。
Scrapy 代理如何工作?
当将整个数据集放入内存中可行(并且希望)时,将使用 Redis。如果我们需要可以由众多进程、应用程序或服务器共享的数据,Redis 是一个很好的选择。我们需要我们的服务器(使用与 Redis 兼容的操作系统)。为了获得这种实用的分布式架构,我们可以利用来自 Linode、Digital Ocean 等公司的优质服务器提供商 API。根据抓取的要求和我们必须抓取这些数据的时间,我们将使用这些 API 构建服务器的数量。此外,需要一个绑定地址设置为 0.0.0.0 的 Redis 服务器。
它基于 Redis 数据库并运行在 scrapy 代理池框架上,允许 scrapy ip 代理 启用分布式技术。 Redis 数据库的项队列、请求队列和请求指纹集合由 Slaver 和 Master 端共享。下载器、解析器、日志和异常处理都包含在称为 Scrapy 的多线程、扭曲处理框架中。虽然对于爬取单个固定网站的增长有优势,但是对于同时爬取100个网站的多站点爬取来说,修改和扩展并不容易。
以下说明演示了如何使用 scrapy Redis。要使用scrapy-redis,我们必须首先在我们的电脑上安装这个包。
1.使用pip命令,我们先安装scrapy-Redis包。
下面的示例演示了 Scrapy Redis 的安装。由于我们已经在我们的系统上安装了 scrapy-Redis 包,下面的示例将显示满足条件并且不需要进一步的操作。
代码:
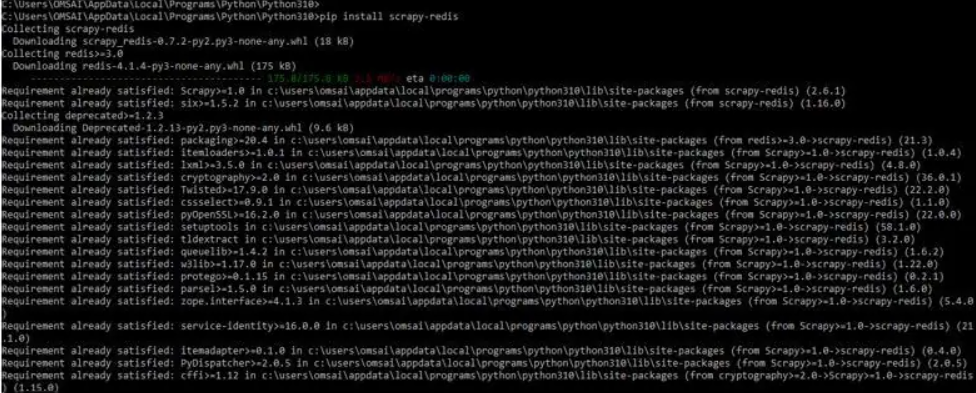
点安装scrapy-redis
输出:
2、使用python命令,我们在这一步安装好Scrapy后登录Python shell。
代码:
Python
输出:

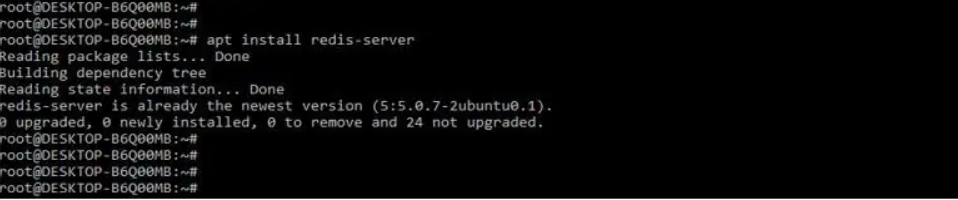
3.安装scrapy-redis包后,我们必须在我们的系统中设置Redis数据库服务器。在下面的示例中,我们的系统上正在安装 redis 数据库服务器。
代码:
安装 redis 服务器
输出:
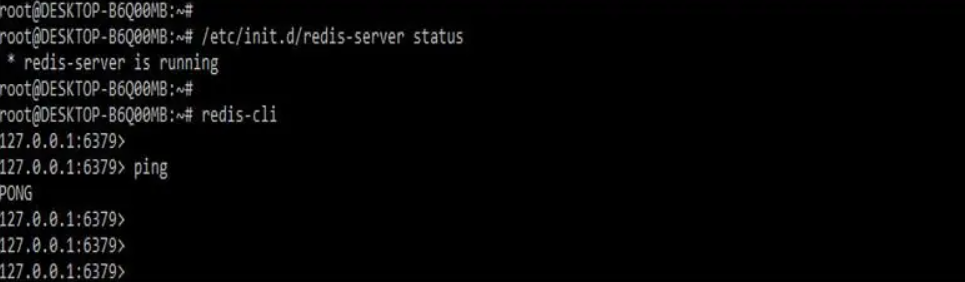
4.在步骤3安装redis服务器之后,我们验证redis服务器的状态如下。
代码:
/etc/init.d/redis-server 状态
redis-cli
输出:
URL 权重删除
一个经常被忽略的对图像文件大小的实质性影响正在缩小颜色托盘。登陆页面的图像通常使用与品牌徽标相结合的简单配色方案。浏览器在加载后将它们存储在缓存中的事实是当访问者第一次到达页面时包含库的另一个原因。
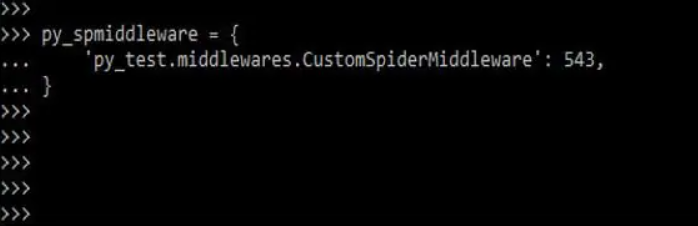
如下示例所示,URL 权重去除。我们首先更改蜘蛛的中间件。
代码:
py_spmiddleware = {
‘py_test.middlewares.CustomSpiderMiddleware’: 543,
}
输出:
在下面的示例中,我们通过添加带有蜘蛛中间件的 scrapy 来减轻数量。
代码:
py_spmiddleware = {
‘py_test.middlewares.CustomSpiderMiddleware’: 543,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware’:无,
}
输出:

服务器上的 HTTP 标头可以处理初始请求并随后调用网页。这种技术可以减少 HTML 的数量,使网页显着更轻。此外,在整个页面中使用内联样式,而不是加载整个样式。使用 CSS 文件可以有效地减少登录页面的重量。这不仅使主页的整体尺寸更小。
Scrapy Redis 项目
我们在下面的示例中使用了 GitLab 项目。
此外,我们可以使用 git 来安装配置。下面的示例演示了如何使用 git 来安装设置,如下所示。
代码:
$ git clone https://github.com/darkrho/scrapy-redis.git
$ cd scrapy-redis
$ python setup.py 安装
输出:
我们使用爬网来运行项目,因为在这个阶段设置是成功的。
代码:
$scrapy crawl dmoz
输出:

结论
它是一个 NoSQL 键值数据存储。 准确地说,它是数据结构的服务器。 它是一个用于网络爬取和结构化数据提取的框架,可应用于许多任务,包括数据挖掘、信息处理和历史保存。