
Python爬虫不可不知的10个高效数据清洗方法(一)
在爬虫工程师的工作流中,数据清洗并入库,是这个爬虫环节中的最后一步,是繁琐且需要耐心的一个环节。
如果企业需要爬取成千上万个网站,那么还会拆分出一个岗位,数据清洗工程师,专注于数据清洗的工作。
本文汇总小编日常爬虫过程中使用最多的10个高效数据清洗方法。
1.XPath
是小编日常在爬虫过程中使用频率最高的一个HTML文件清洗方法,但你熟练掌握后,可以解决90%以上的爬虫数据清洗问题。所谓“一招鲜,吃遍天”。
使用场景:爬虫返回的数据为HTML格式,数据嵌套在HTML代码中。
这里小编以财富中国网站500强企业的数据为例,详细介绍xpath的用法。
示例数据源:
https://www.caifuzhongwen.com/fortune500/paiming/global500/2024_%e4%b8%96%e7%95%8c500%e5%bc%ba.htm
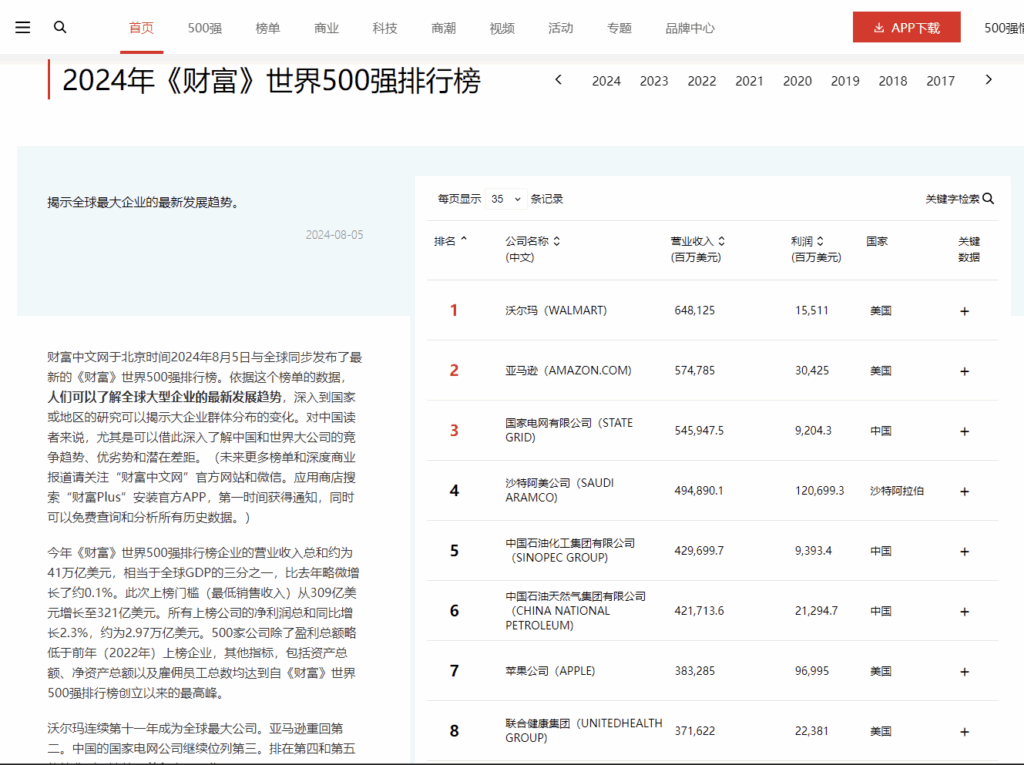
按下浏览器F12,进入开发者菜单。可以在Network中看到HTML源码数据
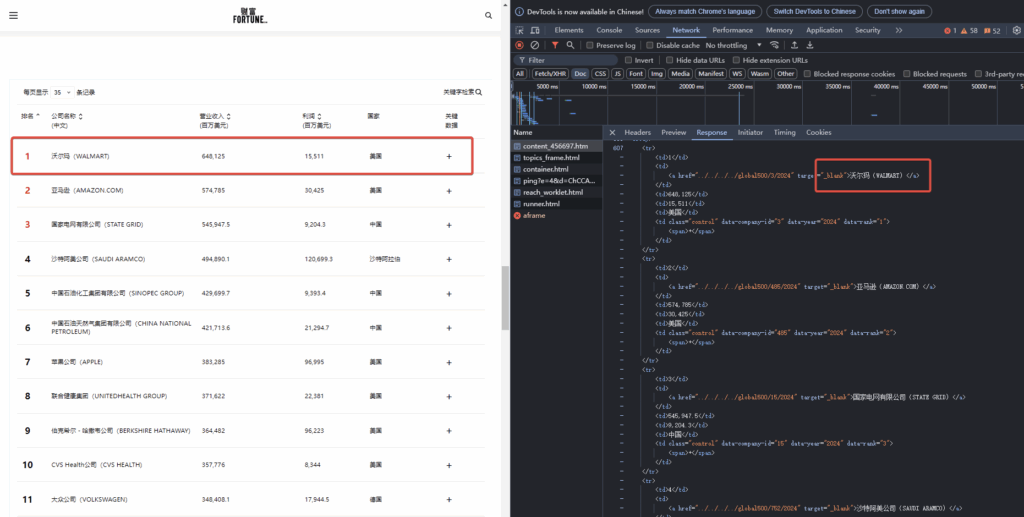
可以看到这个500强的企业数据就在HTML代码里面。
这个页面的代码并没有设置复杂的反爬限制。直接可以用requets就可以获取。
python获取HTML数据,可以参考:https://www.2808proxy.com/practical-application-of-crawler/crawl-html-pages/
import requests
url = "https://www.fortunechina.com/fortune500/c/2024-08/05/content_456697.htm"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36',
}
response = requests.request("GET", url, headers=headers)
response.encoding='utf8'
print(response.text)Code language: Python (python)返回的是HTML数据,里面也包含了数据,找到table表格的数据,截取前面3行,HTML代码如下:
<div class="hf-right word-img2">
<div class="word-table">
<div class="wt-table-wrap">
<table id="table1" class="wt-table">
<thead>
<tr>
<th width="10%">
<span>排名</span>
</th>
<th>
<span>公司名称</span>
<em>(中文)</em>
</th>
<th width="20%">
<span>营业收入</span>
<em>(百万美元)</em>
</th>
<th width="13%">
<span>利润</span>
<em>(百万美元)</em>
</th>
<th width="15%">
国家<br/>
</th>
<th class="key" width="10%">
<em>关键</em>
<em>数据</em>
</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>
<a href="../../../../global500/3/2024" target="_blank">沃尔玛(WALMART) </a>
</td>
<td>648,125</td>
<td>15,511</td>
<td>美国</td>
<td class="control" data-company-id="3" data-year="2024" data-rank="1">
<span>+</span>
</td>
</tr>
<tr>
<td>2</td>
<td>
<a href="../../../../global500/485/2024" target="_blank">亚马逊(AMAZON.COM) </a>
</td>
<td>574,785</td>
<td>30,425</td>
<td>美国</td>
<td class="control" data-company-id="485" data-year="2024" data-rank="2">
<span>+</span>
</td>
</tr>
<tr>
<td>3</td>
<td>
<a href="../../../../global500/15/2024" target="_blank">国家电网有限公司(STATE GRID) </a>
</td>
<td>545,947.5</td>
<td>9,204.3</td>
<td>中国</td>
<td class="control" data-company-id="15" data-year="2024" data-rank="3">
<span>+</span>
</td>
</tr>
</tbody>
</table>
</div>
</div>
</div>Code language: HTML, XML (xml)首先需要把上面的HTML代码传递给xml解析库,这里推荐使用parsel
在shell或者cmd里面 使用pip安装
pip install parsel然后python代码使用
from parsel import Selector
resp = Selector(text=response.text)Code language: Python (python)然后开始解析节点。
数据在<tbody>下面,然后需要逐个往上,唯一定位到这个tbody。
<div class="hf-right word-img2">
<div class="word-table">
<div class="wt-table-wrap">
<table id="table1" class="wt-table">
<thead> ..... </thead>
<tbody>....</tbody>Code language: HTML, XML (xml)xpath语法里,定位标签使用 // , 例如定位HMTL里所有的<div>标签,使用
resp.xpath('//div')Code language: JavaScript (javascript)这样会返回所有的div标签。但这样会返回大量数据,很多不是我们想要的哦。所以我们就需要继续根据属性过滤掉不需要的。
属性定位是用 [@属性名=”属性值”], 上面的第一个div标签 <div class=”hf-right word-img2″>
resp.xpath('//div[@class="hf-right word-img2"]')Code language: JavaScript (javascript)然后子标签 <div class=”word-table”>,就一步一步往下
resp.xpath('//div[@class="hf-right word-img2"]/div[@class="word-table"]')Code language: JavaScript (javascript)子标签继续往下,如法炮制
resp.xpath('//div[@class="hf-right word-img2"]/div[@class="word-table"]/div[@class="wt-table-wrap"]')Code language: JavaScript (javascript)最后可以定位到table表格下的tbody
resp.xpath('//div[@class="hf-right word-img2"]/div[@class="word-table"]/div[@class="wt-table-wrap"]/table/tbody/tr')Code language: JavaScript (javascript)而上面的xpath数据返回的是一个list。
[<Selector query='//div[@class="hf-right word-img2"]/div[@class="word-table"]/div[@class="wt-table-wrap"]/table/tbody/tr' data='<tr><td>1</td><td><a href="../../../....'>,
<Selector query='//div[@class="hf-right word-img2"]/div[@class="word-table"]/div[@class="wt-table-wrap"]/table/tbody/tr' data='<tr><td>2</td><td><a href="../../../....'>,
<Selector query='//div[@class="hf-right word-img2"]/div[@class="word-table"]/div[@class="wt-table-wrap"]/table/tbody/tr' data='<tr><td>3</td><td><a href="../../../....'>,
<Selector query='//div[@class="hf-right word-img2"]/div[@class="word-table"]/div[@class="wt-table-wrap"]/table/tbody/tr' data='<tr><td>4</td><td><a href="../../../....'>,
..... 我是省略号 .......Code language: HTML, XML (xml)这个list的长度刚好是500,对应的500个财富公司的名称列表。

列表里的每一个元素类型也是一个xpath,对应的一个企业的数据。所以需要对每个xpath继续解析。
for node in nodes:
num = node.xpath('./td[1]/text()').extract_first()
name = node.xpath('./td[2]/a/text()').extract_first()
income = node.xpath('./td[3]/text()').extract_first()
profit = node.xpath('./td[4]/text()').extract_first()
country = node.xpath('./td[5]/text()').extract_first()
print(num,name,income,profit,country)Code language: PHP (php)子xpath需要从./ 开始继续遍历。接着是td标签,td[1] 代表第一个td标签,td[2]代表第二个标签;这里要提醒的是,它的下标并不像数组那样从0开始,而是从1开始。
最后的text() 方法为提取出标签内容,返回的是一个list,所以extract_first提取出来第一个内容。
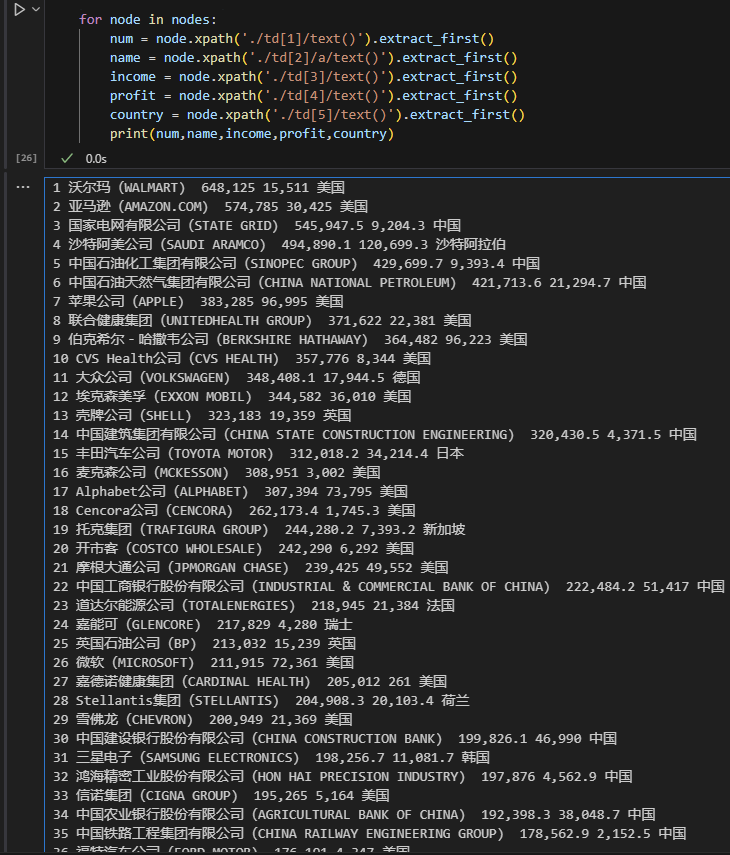
这样子数据就轻松拿到手了,是不是很简单了呢?
在这个基础上,咱们可以做点基础的数据统计工作,比如统计一下500强企业里,中国的企业有多少家,是美国的多,还是中国的多。
cn_count=0
us_count=0
for node in nodes:
num = node.xpath('./td[1]/text()').extract_first()
name = node.xpath('./td[2]/a/text()').extract_first()
income = node.xpath('./td[3]/text()').extract_first()
profit = node.xpath('./td[4]/text()').extract_first()
country = node.xpath('./td[5]/text()').extract_first()
if country =='中国':
cn_count+=1
print(num,name,income,profit,country)
if country=='美国':
us_count+=1Code language: PHP (php)输出的结果:
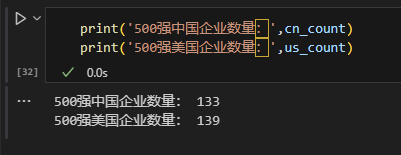
厉害我的国!2024年500强企业数,中美之间的差距只差了6个企业,2025年大概率会超越美帝,成为500强公司最多的国家!
本demo完整源码:https://github.com/Rockyzsu/crawler_data_processing/blob/master/xpath_example.py
上面是xpath的基本用法,然后xpath的完整定位语法如下:
节点
xpath('//div'):选取所有div节点,并包含它所有的子节点;
xpath('x/div'):选取 x 节点的下一层所有div节点,若 x 没有则从根节点开始;
xpath('x/..'):选取 x 节点的父节点;
xpath('div/text()'):获得 div 标签中的 text 值;
xpath('div/@class'):获得 div 标签中 class 属性的值,class 可替换为其他属性名;
xpath('div/@*'):获得 div 标签中所有属性的值;
xpath('div/*'):选取 div 节点下所有子节点;
xpath('div/*/span'):选取 div 节点下第二级所有span节点;
xpath('div/node/name()'):获得node节点的名字;
谓语
xpath('/body/div[1]'):选取 body 下第一个 div 节点;
xpath('/body/div[last()]'):选取 body 下最后一个 div 节点;
xpath('/body/div[last()-1]'):选取 body 下倒数第二个 div 节点;
xpath('/body/div[position()<=3]'):选取 body 下前三个 div 节点;
xpath('/body/div[not(@class)]'):选取 body 下不含 class 属性的 div 节点;
xpath('/body/div[not(@class=”zhang”)]'):选取 body 下不含 class 属性值等于 zhang 的 div 节点;
xpath('/body/div[@class]'):选取 body 下含有 class 属性的 div 节点;
xpath('/body/div[@class=”zhang”]'):选取 body 下 class 属性值等于 zhang 的 div 节点;
xpath('/body/div[contains(@class,”zhang”)]'):选取 body 下 class 属性值含有 zhang 的 div 节点;
轴
xpath('//a|//div'):选取所有的 a 节点和 div 节点;
xpath('/div/self::*'):选取当前 div 节点;
xpath('/div/parent::*'):选取 div 节点的父节点;
xpath('/div/ancestor::*'):选取 div 节点的所有先辈节点(父、祖父);
xpath('/div/ancestor-or-self::*'):选取 div 节点的所有先辈节点包含自身(可以指定节点,将* 替换为节点名);
xpath(/div/preceding::* ):选取 div 节点之前的所有节点(可以指定节点,将 * 替换为节点名);
xpath('/div/preceding-sibling::*'):选取 div 节点之前的所有兄弟节点(可以指定节点,将* 替换为节点名);
**xpath('/div/following::\*[1]****'):选取 div 节点之后的所有节点(可以指定节点,将** **替换为节点名); 后面第一个节点**
配和模糊匹配,食用更佳
比如要提取<div class=”good”>标签里面的超链接<a href=’http://xxxx.com/1.jpg’>,<a href=’http://xxxx.com/2.jpg’>,<a href=’http://xxxx.com/3.jpg’>,<a href=’http://xxxx.com/4.jpg’>, 那么可以使用xpath的属性模糊匹配,使用的是contains(@属性,匹配值)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
上面功能写出来就是:
result = Selector(text=response.text).xpath('//div/a[contains(@href, "http://xxxx.com")]')Code language: JavaScript (javascript)这样的话就自过滤出div下a的超链接格式包含http://xxxx.com的节点。
熟练掌握xpath的html定位解析,是大部分爬虫工程师的必经的历练之路。
2. pandas read_html
对于获取HTML里的表格数据,其实有一个偷懒的办法,那就是pandas的read_html。
pandas的安装:
pip install pandas使用场景:清洗的数据在HTML的table标签之中。
前面的500强企业的数据就是满足这样的一种场景。
咱们只需要使用一句语句pd.read_html,就把全部提取出来。不需要像上面xpath那样,一个字段一个字段那样提取。
直接上代码:
from io import StringIO
import pandas as pd
df = pd.read_html(StringIO(response.text))[0] # 这里获取html第一个表格的数据,如果多个table,根据索引获取
print(df.head())Code language: PHP (php)就这样,就把表格里的全部数据提取出来了。
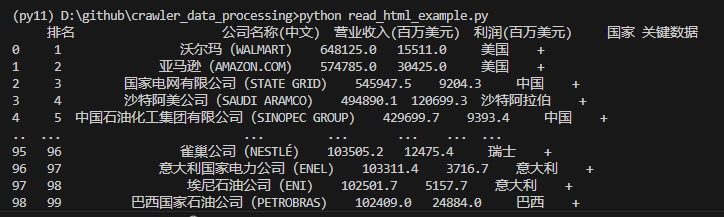
而pandas更为方便,它可以用一条语句把数据导出到Excel,MySQL等外部数据。
df.to_excel(‘500强企业.xlsx’) # 导出到excel文件
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@localhost/Test')
df.to_sql(‘500强企业’,con=engine) #导出到MYSQL数据Code language: PHP (php)而且有了pandas之后,做数据分析就像吃生菜一样简单。
比如按照国家对500强企业数量分布,进行排序。
df['国家'].value_counts()
Code language: CSS (css)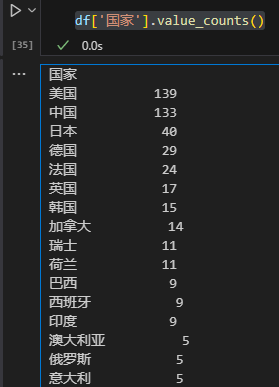
在500强企业数量上,中美两国是断层式遥遥领先。而第三名和第四名的日本德国加起来只有69家。
本demo完整源码:https://github.com/Rockyzsu/crawler_data_processing/blob/master/read_html_example.py
不过小编在高频反复爬取这个财富中国网站500强企业网站的时候,后面就连接不上了。
返回的报错信息:
requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.fortunechina.com', port=443): Max retries exceeded with url: /fortune500/c/2024-08/05/conrequests.exceptions.ProxyError: HTTPSConnectionPool(host='www.fortunechina.com', port=443): Max retries exceeded with url: /fortune500/c/2024-08/05/content_456697.htm (Caused by ProxyError('Cannot connect to proxy.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)))Code language: JavaScript (javascript)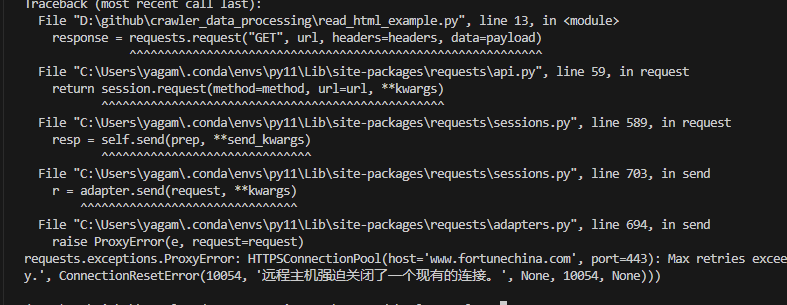
估计被封了,所以爬虫必不可少的一个工具就是代理IP,一旦当前IP被封锁,那么通过切换代理IP,就能轻松绕过封锁。
这里可以提供免费试用的代理IP,https://www.2808proxy.com/product/,需要的读者朋友可以试试。
添加代理后的获取HTML数据的代码如下:
USERNAME = '您的账号'
PASSWORD = '您的密码'
getIPUrl= '您的一键生成提取IP的HTTP接口'
import requests
import time
if __name__=='__main__':
#第一步:获取ip列表
getIPUrl = 'https://api.2808proxy.com/proxy/unify/get?token=xxxxx&amount=1&proxy_type=http&format=json&splitter=rn&expire=300'
req = requests.get(getIPUrl)
print(req.json())
#第二步:通过代理ip发送请求
proxy_url_secured = "%s://%s:%s@%s:%d" % ('http', USERNAME,PASSWORD,req.json()['data'][0]['ip'], req.json()['data'][0]['http_port_secured'])
r = requests.get('https://www.fortunechina.com/fortune500/c/2024-08/05/content_456697.htm', proxies={'http':proxy_url_secured, 'https':proxy_url_secured})
print("Response with proxy : " + r.text)
print("sleeping...")
time.sleep(1)Code language: PHP (php)只需要在requests的时候把 proxies设置为:{‘http’:proxy_url_secured, ‘https’:proxy_url_secured} 即可。
因为篇幅有限,下一篇继续介绍剩余的数据清洗方法